Will India have its own AI model?
Though funding remains limited, efforts are underway to launch India's own multilingual low-cost generative AI
Last Updated: Feb 25, 2025, 11:44 IST7 min

The emergence of China’s DeepSeek, which is said to have been built at a small fraction of the cost compared to OpenAI’s GPT large language models (LLMs), has sparked excitement among India’s artificial intelligence (AI) scientists and engineers to build a home-grown LLM from scratch. India is entirely reliant on models such as OpenAI’s proprietary GPT or Meta’s Llama, an open-source model. It is OpenAI"s second-largest market by number of users, said the company’s CEO Sam Altman during his visit to Delhi earlier in February. India also accounts for about 15.6 percent of DeepSeek’s AI chatbot downloads, according to AppFigures.
DeepSeek’s makers, Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co, say they spent only $5.576 million on training the model on H800 processors from Nvidia these processors were designed to meet the restrictions placed on the chipmaker by the US government on exports to China. Some experts have pointed out that based on DeepSeek’s workload, the chips were equivalent to Nvidia’s H100 GPUs (graphical processing units).
In comparison, OpenAI’s GPT-4 is said to have cost $80-100 million to train, apart from the cost of developing the actual model itself and developing each new iteration. OpenAI’s 2024 losses were projected at $5 billion, CNBC reported last September. Such prohibitive costs had deterred any serious attempts to develop an AI model in India, but now DeepSeek seems to have changed that.
“The government is now asking us to build models for them. We"re well-positioned to deliver, as we"ve already developed a model comparable to GPT," says Vishnu Vardhan, founder and CEO of Hanooman AI, which is developing multilingual, multimodal LLMs, including one named Everest 1.0.
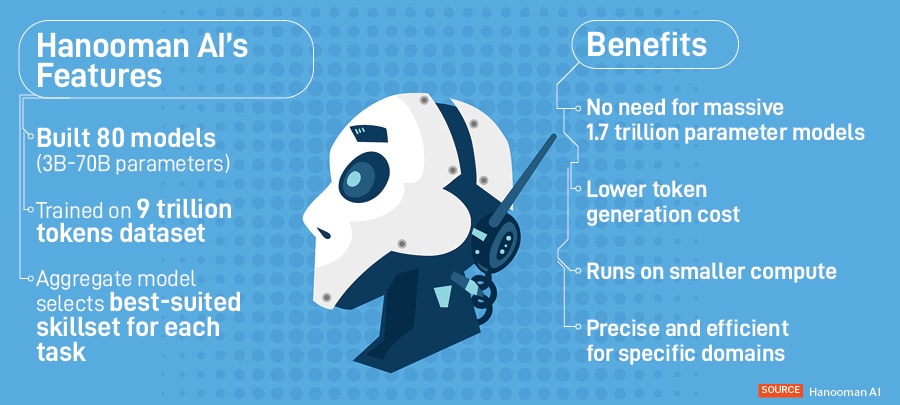
India"s AI mission proposes subsidising chips for application and product development, but Vardhan has advocated for allocating funds to build foundational technology as well. LLMs, focussed on text-based tasks, can be seen as a subset of foundation models, which a broader set of general-purpose AI models that can perform a range of natural language processing-based tasks.
Investors have remained hesitant to fund foundational projects, citing high costs and uncertainty. With growing interest from the government and large companies, key stakeholders have now started showing interest, explains Vardhan, who is developing a generative AI model with 9 trillion data points, which he says will operate at a significantly lower cost.
“By hosting our model on Indian servers, we"ve reduced costs to nearly one-third of DeepSeek"s token costs. This will make our model extremely affordable, enabling widespread adoption and potentially disrupting the market," he adds. He plans to release the model by April.
A big challenge in India is its diversity of languages, with 22 scheduled languages and hundreds of dialects and so on it is a problem that doesn’t exist in the English-speaking world or in China. Most existing AI models struggle with India-specific use cases due to a lack of training data.
“Our next generation is mixing English with Hindi characters, so AI needs to be multilingual, understand dialects, and understand nuances," says Pranav Mistry, founder of TWO AI, a multilingual and cost-efficient language model startup building from Silicon Valley for the Asian market.
TWO AI recently introduced Sutra-R0, a reasoning model for structured thinking and complex decision-making in various languages and domains. The model addresses enterprise and consumer needs with its efficient resource usage and multilingual capabilities. Backed by a $20-million seed fund from Jio Platforms (a subsidiary of Reliance Industries, publishers of Forbes India) and South Korean internet conglomerate Naver, TWO AI’s ChatSutra has 1.5 million users in multiple languages, including Gujarati, Chinese, Thai, Vietnamese, and Indonesian.
“In our first revenue-generating quarter, we made $7 million [last quarter]. This quarter, we"ve already reached a $10 million run rate," adds Mistry, who launched TWO AI three and a half years ago. The company is working with major banks in South Korea and India, finance institutions, mortgage groups, and retail applications.
Sutra’s makers say it was “trained from scratch" and developed over a period of 18 months. They fed it a mix of open and proprietary datasets, allowing it to learn structure, grammar, facts, and reasoning on its own. This has made it more cost-efficient to train and run, particularly in non-English languages, where it outperforms some existing models, they say.

India also needs better localised datasets. Government-backed Bhashini, a language translation technology project, and IT services company Tech Mahindra’s Project Indus have also built models tailored to the country"s linguistic diversity. Bhashini has created an open-source Indic language dataset to expand internet accessibility in Indian languages like Hindi, Tamil, and Bengali.
“We"ve developed our models from square one, leveraging encoder-decoder technologies and other fundamental AI technologies. To achieve this, we collaborated with approximately 70 research institutes across India," says Amitabh Nag, CEO of Bhashini, which enables real-time speech translation in 22 languages.
Currently, it’s processing about 3.6 million inferences daily, with 166 million inferences in January alone. “If OpenAI wants to support English and a few other languages, we step in as the translation engine. We translate customer input from their local language to English, which is then processed by OpenAI"s prompt engineering. The response is then translated back to the customer"s local language," explains Nag.
Tech Mahindra’s Project Indus, launched last year in collaboration with Dell Technologies and Intel, created an AI model that understands and communicates in multiple Indic languages and dialects, starting with Hindi and its 37 variations. The differentiator of this project is its efficiency, says Nikhil Malhotra, chief innovation officer & global head of AI and Emerging Technologies at Tech Mahindra. “It’s built with an investment of less than $400,000. It demonstrates how high-quality AI solutions can be developed without high costs, making it an attractive model for enterprise adoption."
Shortly after the launch of DeepSeek, Government of India’s IndiaAI Mission invited proposals from startups, researchers, and entrepreneurs to build foundation models for the country. The models can be LLMs or small language models (SLMs) across multimodal text, voice, or video. IndiaAI will fund these through grants, compute credits, or equity investment.
So far, the government has received over 60 proposals, which include players like Sarvam AI, CoRover.ai, and Ola’s Krutrim. The plan is to develop the country"s own AI model within the next nine to 10 months, as promised by Minister of Electronics & IT Ashwini Vaishnaw.
“We"ve received 69 proposals—a testament to the ecosystem"s capabilities and confidence," says Abhishek Singh, additional secretary, MeitY, and CEO of IndiaAI Mission. “The government will provide funding, but ultimately, venture capital [VC] firms and other investors must also contribute. Together, they"ll need to collaborate to build something state-of-the-art, comparable to the world"s best."
Rahul Agarwalla, managing partner at SenseAI, an early-stage VC investing in AI-first startups, echoes Nandan Nilekani, former chairman of India’s Unique ID Authority, who has emphasised the need for population-scale AI applications. “Practically, we should focus on building applications that deliver value to people," he says. “When I speak with founders, I emphasise the importance of solving real problems. While we support efforts to build LLMs, it"s not a prerequisite for success."
Last year, $100 billion was invested in AI ventures worldwide, adds Agarwalla almost 50 percent of US VC fund went to AI companies. In contrast, India received just $1 billion, accounting for only 1 percent of global AI investments.
Indian homegrown AI models will have to compete with established players such as OpenAI and Google and other deeply funded ventures such as Anthropic.
“The question remains: Is there a market for Indian homegrown models?" says Neil Shah, co-founder and vice president of research at Counterpoint Technology Market Research. “While it"s possible to use global foundational models and train them with Indian data for local applications, creating a homegrown foundational model is a significant challenge."
Sarvam AI, in Bengaluru, is exploring building on top of open-source models. Its Sarvam 1 model was built entirely from scratch, explains co-founder Vivek Raghavan, “but other models may be a combination of our development and open-source components. The approach varies depending on the application and requirements."
The venture is preparing to submit a proposal to the Ministry of Electronics and IT to develop India"s first indigenous foundational AI model. With the ministry announcing that at least six teams will undertake this ambitious project, Sarvam AI is positioning itself as a key contender. Sarvam AI plans to launch its foundational models by year-end, offering advanced capabilities in reasoning, research, and query-answering without relying on external supplements.
In making AI a reality in India, Raghavan sees three main challenges beyond investments: Building large models requires skilled professionals, access to relevant data is crucial, and managing computational resources efficiently. “These three ingredients—talent, data, and compute—are essential for success. With the right combination of these elements, I believe we can make significant progress in AI adoption in India," he says.
First Published: Feb 25, 2025, 11:44
Subscribe Now